




- 何为计算机?能否自主搭建计算机系统
拆开计算机,你发现里面是一对电路!电路就是计算机的雏形! 试想一下你有一大把灯泡,你想表示数字1,那么你就通电让一个灯泡亮起,你想表示数字2
- 何为进制?计算机为何用二进制?
什么是进制 所谓进制就是计算者(人/或者机器)进行算术运算时的数据累计的规则,比如十进制,它的累计规则就是逢十进一,0到9为数码, 只是不同的文化中,数码符号有所不同,
- 计算机组成结构介绍
先看一张图:想象一下我们在做化学实验:输入设备就是原材料,计算机要计算哪些数据,怎么计算,都来自于输入设备。 内存就是烧杯,把原材料倒进烧杯,计算机要把来自输入设备的数据
- 计算机通信的原理是什么?
通信概念: 通信就是把信息从自然界里捕捉到然后再转化成易处理的信息然后再通过各种方法传输最后到了信息处理的终端计算机这里,计算机处理信息后再把信息通过各种各样的方式
- 软件是什么?真的有软件吗
世界上没有软件!软件只是从功能方面的一种说法。 软件的由来 比如我有一张白纸,我在上面扎一个孔然后放在太阳底下就能看见一个小圆点。这个小圆点代表1。现在我让你写一个
- 软件(代码)如何控制硬件?
先说代码(软件): 我们是用电脑的键盘来输入的指令,敲入代码,其实就是通过键盘敲入高低电平,你所看到代码是这些电压的高低控制显示器所显示的图像,其实电脑也不知道它是什
- 编码是什么?为何会有乱码?字符集与编码区别
编码引入 我们用阿拉伯数字1代表只有一个事物。英国人用字母one代表只有一个事物!我们管老虎叫做老虎,英国人管老虎叫做tiger。描述同样的事物不同的人用了不同的方式。假定英国
- 数据库的本质是什么?
数据库是什么? 如果去看百度百科,你将永远不知道数据库是什么?因为他用你不懂的东西去解释另一种你不懂的东西!很多小白学东西很困难,原因就是他对某个事物没有概念,但网
- 什么是操作系统?
操作系统是什么 计算机本身是一堆破铜烂铁加一些电路再加一些磁盘之类的物质,这些电路嵌入了人类的逻辑思维所以叫逻辑电路,人类设计的这些电路可以做加法可以做判断,同时像
- 软件真的建立在操作系统之上吗?
认知误区 很多人说软件建立在操作系统之上,这给人的感觉是软件凌驾于系统之上一样,这种说法本意是从逻辑上表达两者的关系却给人传递了错误的认知,这种表述不够本质,不够准
- 编程语言和操作系统是什么关系?
首先需要知道编程语言是是可运行的计算机程序的一种表达方式,说白了就是可以驱动计算机内部各种电路的电信号。而操作系统本身是一个程序,也是运行在计算机上的,也是编程语
- 为何说高级语言不算编程语言?
数学老师给学生讲四则运算,有一套约定俗成的符号规则比如+代表加,=代表相等。如果你狠奇葩,非要让-代表加那也是没问题的。只要告诉同学当你的眼睛看到-这个字符时大脑要进行
- win10鼠标和窗口间歇性卡顿的原因
在使用Windows10操作系统的时候,电脑鼠标间歇性卡顿和窗口卡住的情况,几秒之后又自动恢复正常,重装了系统就不卡顿了,但是一更新N卡驱动之后又会出现鼠标间歇性卡顿的情况,被
- 华为多任务界面怎么调
每一种操作要体会其中的思路,这样才能举一反三,即使更换机型和软件依然可以自己摸索出来。该教程适用产品型号:华为nova8系统版本:harmonyOS3.0 ;关于华为nova8怎么分屏这个问题
- 华为荣耀50怎么设置锁屏
每一种操作要体会其中的思路,这样才能举一反三,即使更换机型和软件依然可以自己摸索出来。该教程适用产品型号:荣耀 50系统版本:Magic UI 6.1 ;关于华为荣耀50怎么设置锁屏这个
- 华为手机拦截设置在哪
每一种操作要体会其中的思路,这样才能举一反三,即使更换机型和软件依然可以自己摸索出来。该教程适用产品型号:华为p50pro系统版本:harmonyOS3.0 ;关于华为手机拦截设置在哪这个
python基础 python面向对象 python并发编程 python进阶 selenium爬虫
-
 selenium不重启更改代理ip(使用隧道代理)selenium添加代理ip非常简单,直接这样即可: options.add_argument(--proxy-server=http://${ip:port}) # 代理IP:端口 用这个driver请求任何网页都将使用这个代理ip地址。但是我们用selenium采集数据的时候...文章阅读
selenium不重启更改代理ip(使用隧道代理)selenium添加代理ip非常简单,直接这样即可: options.add_argument(--proxy-server=http://${ip:port}) # 代理IP:端口 用这个driver请求任何网页都将使用这个代理ip地址。但是我们用selenium采集数据的时候...文章阅读
-
 selenium谷歌浏览器崩溃out of memory彻底解决想做web自动化,有能力的同学可以自己封装个浏览器,不会的同学就玩chromedriver驱动浏览器并且忍受着他的各种大坑,关于selenium的坑和bug可以参考selenium坑大全、 无论是selenium操作谷歌...文章阅读
selenium谷歌浏览器崩溃out of memory彻底解决想做web自动化,有能力的同学可以自己封装个浏览器,不会的同学就玩chromedriver驱动浏览器并且忍受着他的各种大坑,关于selenium的坑和bug可以参考selenium坑大全、 无论是selenium操作谷歌...文章阅读
-
 selenium控制(接管)本地已打开的浏览器前面我们说过通过一段js把selenium的webdreiver特征全部去除掉后依然可以被检测,遇到这种刁钻的站该怎么办呢?只有用笨方法了。让selenium去控制本地已经正常启动的浏览器。具体实现步...文章阅读
selenium控制(接管)本地已打开的浏览器前面我们说过通过一段js把selenium的webdreiver特征全部去除掉后依然可以被检测,遇到这种刁钻的站该怎么办呢?只有用笨方法了。让selenium去控制本地已经正常启动的浏览器。具体实现步...文章阅读
-
 selenium随机useragent,cookie,headers头自定义人类都知道selenium可以通过option.add_argument()函数 来添加启动配置从而实现UA的定义,但是如果我们想实现每次请求随机一个UA那么这种办法就不合适了!因为启动配置是在driver启动前配置...文章阅读
selenium随机useragent,cookie,headers头自定义人类都知道selenium可以通过option.add_argument()函数 来添加启动配置从而实现UA的定义,但是如果我们想实现每次请求随机一个UA那么这种办法就不合适了!因为启动配置是在driver启动前配置...文章阅读
-
 selenium清除残留chromedriver进程(网上帖子是错的)selenium如果频繁通过chromedriver来启动和关闭谷歌浏览器,那么内存会残留一些chromedriver进程,因为chromedriver并不会随着程序的退出而立刻在内存消失。所以在频繁使用的时候可能感觉到...文章阅读
selenium清除残留chromedriver进程(网上帖子是错的)selenium如果频繁通过chromedriver来启动和关闭谷歌浏览器,那么内存会残留一些chromedriver进程,因为chromedriver并不会随着程序的退出而立刻在内存消失。所以在频繁使用的时候可能感觉到...文章阅读
-
selenium指定目录下载文件且阻止浏览器弹框selenium指定目录下载文件且阻止浏览器弹框该如何配置呢? 网上绝大部分的帖子的配置都不是不起作用的。目前用的谷歌浏览器80版本的,经过测试以下方式完全可以实现该功能。只把...文章阅读
精彩博文
-
【顶】热门关注




-
seo伪原创神器OpenAI下的ChatGpt
OpenAI 是一家人工智能研究机构,它的目标是通过研究人工智能技术来帮助人类解决实际问题,并为世界带来更多的科技进步。 ChatGpt是OpenAI 下的产品,是一种高级自然语言生成模型,它...
阅读更多 指数:36322-12-05
指数:36322-12-05 -
pandas获取及删除某一级索引、多层变为单层索引
pandas创建多重索引后,如果想要得到某一层的索引,则需要通过get_level_values获得。如果想要删除某个层级的索引则可以使用 get_level_values(level=)函数可以接受int或者str类型,int代表索引...
阅读更多指数:24822-08-14 -
pandas创建多重索引的7种方法
pandas创建多重索引有很多方式,老董在使用过程中一共总结了7种类方式,本文为大家总结1下。 1、pd.MultiIndex.from_arrays(): 可以直接传入二维列表作为参数。 # ‐*‐ coding: utf‐8 ‐*‐...
阅读更多指数:28022-08-14 -
from_arrays、from_tuples、from_product、from_frame创建多重
上篇文章我们给pandas创建多重索引是直接给index或者columns参数传递二维列表,这样写起来可能比较麻烦,实际上才pandas中有3个比较常用的方法来创建多重索引,分别介绍如下。 1、fro...
阅读更多指数:45422-08-14 -
pandas的多重索引index、columns、索引值、names属性及
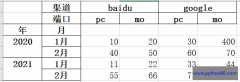
上篇文章通过从excel读取数据来生成多重索引的df,本节我们从头来认识下pandas的多重索引,对其有1个整体的概念。我们先通过index和columns参数来创建1个多重索引的df。 要创建多重索引...
阅读更多指数:49422-05-03 -
pandas多重索引标准样式(写入excel有空行)
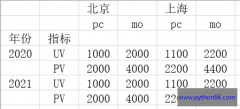
pandas的列索引和行索引都可以有name属性(多重索引就是names属性),所以一旦涉及多重索引,pandas需要预留位置来展示多重索引可能存在的names属性,因此在一些展示上可能和我们想的不同...
阅读更多指数:33722-05-01 -
pandas多列变多行(即宽表变长表)melt和stack函数
多行转多列和多列转多行是较为常见的操作,上一篇文章介绍了pandas多行变多列(即长表变宽表)操作,本文介绍pandas多列变多行(即宽表变长表)操作,分别用melt和stack来实现。 1、...
阅读更多指数:46422-05-01 -
pandas多行转多列(长表变宽表)pivot和unstack
pandas处理数据除了对数据进行加减乘除、关联、分组等之外,还会涉及对数据进行变形操作,比如多行转多列,多列转多行,本文介绍下pandas多行变多列(即长表变宽表)操作,分别用...
阅读更多指数:14722-05-01 -
pandas transform用法详解(多个案例)
pandas的transform函数可以被很多对象调用,比较常见的是Series对象、DataFrame对象、DataFrameGroupBy对象、SeriesGroupBy对象,我们分别来讲解下。 1、Series对象调用transform() Series.transform(func,axis...
阅读更多指数:32122-04-12 -
pandas的groupby使用apply分组排序
前面的文章依次介绍过pandas分组操作中高频出现的函数,如agg、transform、filter,如果想彻底了解pandas分组聚合各类操作可以查看 pandas的groupby使用大全 。 在实际处理数据中,pandas分组后...
阅读更多指数:23222-04-04
热门推荐


站点信息
- 网站程序:PHP
- 客服微信:a772483200
