
requests爬虫
Tips:编程是工科,多动手、付出必有回报。
博文目录
-
【顶】好评文章推荐




-
什么是爬虫?爬虫的本质是什么?爬虫有什么用

什么是爬虫? 爬虫通俗的解释就是复制粘贴!你在浏览器上点开一个网址,复制这个页面的一些信息,保存到自己的文件!这个过程如果用程序来实现,那么这个程序就叫做爬虫! 研...
阅读更多 指数:18020-04-06
指数:18020-04-06 -
什么是协议?到底什么是网络协议?

什么是协议? 协议通俗的说就是规矩谁能立规矩呢,只有人。 生活中,协议无处不在,比如说我们把会发出汪汪声音的动物叫做狗,我们见了一条狗,我们说这是一条狗。这就是一种...
阅读更多指数:13920-04-06 -
http和https协议讲解-通俗而透彻
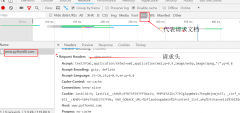
在两条电脑可以通信的基础上,不同的协议就是代表两者之间不同的话术。http和https协议是搞爬虫接触比较频繁的协议。https相比http多了一层加密算法使得数据传输更加安全。但是htt...
阅读更多指数:23920-04-06 -
requests库安装及常用操作介绍

python爬虫模块有两种比较常见,第一种为urllib模块,第二种为requests模块。urllib模块比较恶心,需要手动处理url编码、post请求参数等,requests模块出现后,就快速的代替了urllib模块。 但...
阅读更多指数:37619-07-18 -
requests的get请求及自定义请求头header
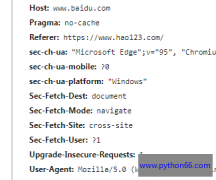
基于requests模块的简单get请求。 需求:爬取百度首页。 注意User-Agent: User-Agent:请求载体的身份标识,使用浏览器发起的请求,请求载体的身份标识为浏览器。 User-Agent检测:网站通过...
阅读更多指数:23719-07-18 -
requests的get请求url传参及无效参数
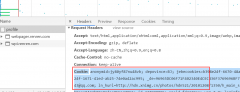
需求:在百度搜索www.python66.com,然后将搜索结果保存到文件bd_python66.html 百度搜索的url:https://www.baidu.com/s?wd=搜索词 解决:利用params参数,代码如下: # -*- coding: utf-8 -*-import requestsim...
阅读更多指数:27019-07-18 -
requests获取状态码与http响应头、请求头
HTTP协议中没有规定post提交的数据必须使用什么编码方式,服务端根据请求头中的 Content-Type 字段来获取编码方式,再对数据进行解析。具体的编码方式包括如下: - application/x-www-form-...
阅读更多指数:39119-07-18 -
requests的url重定向次数与禁用处理
NO1: Requests 可以为 HTTPS 请求验证 SSL 证书,就像 web 浏览器一样。SSL 验证默认是开启的,如果证书验证失败,Requests 会抛出 SSLError。在该域名requestb.in上我没有设置 SSL,所以失败了。代...
阅读更多指数:49319-07-18 -
什么是Cookie,requests处理Cookie的多种方法
代理 如果需要使用代理,你可以通过为任意请求方法提供proxies参数来配置单个请求: 你也可以通过环境变量HTTP_PROXY和HTTPS_PROXY来配置代理。 若你的代理需要使用HTTP Basic Auth,可以使用...
阅读更多指数:11619-07-19 -
requests请求超时处理与异常总结
http://2.python-requests.org/zh_CN/latest/user/quickstart.html#id4...
阅读更多指数:42819-07-18 -
requests响应r.text(文本数据)与r.json()(json数据)
Cookies 如果一个响应中包含了cookie,那么我们可以利用 cookies参数拿到: # -*- coding: utf-8 -*-import requestsdef get_html(url,retry=2): try: r = requests.get(url=url, headers=headers, stream=True) except Exception as...
阅读更多指数:39720-09-27 -
requests二进制响应r.content下载图片视频及解码gzip和deflate
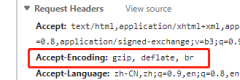
Cookies 在京东A页面购买了A商品,然后B页面购买B商品,C页面买C商品。最后订单中可以显示出所有商品。为什么呢?说明服务器对用户有1个标记。这种标记如何实现呢? 浏览器访问网页...
阅读更多指数:25021-11-10




站点信息
- 网站程序:Laravel
- 客服微信:a772483200
