您的位置: 网站首页> requests教程> 当前文章
http和https协议讲解-通俗而透彻
![]() 老董-我爱我家房产SEO2020-04-06196围观,129赞
老董-我爱我家房产SEO2020-04-06196围观,129赞
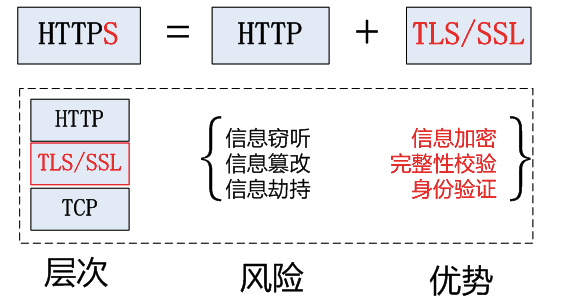
在两条电脑可以通信的基础上,不同的协议就是代表两者之间不同的话术。http和https协议是搞爬虫接触比较频繁的协议。https相比http多了一层加密算法使得数据传输更加安全。
浏览器打开一个网址其实就是发http/https请求给网页服务器,服务器返回页面给浏览器。爬虫要做的就是代替浏览器发请求并接受传输来的页面数据!

http/https请求都包含请求行、请求头部、空行、请求数据四部分,http/https响应包含状态行、消息报头、空行、响应正文四部分!一个典型的HTTP示例:
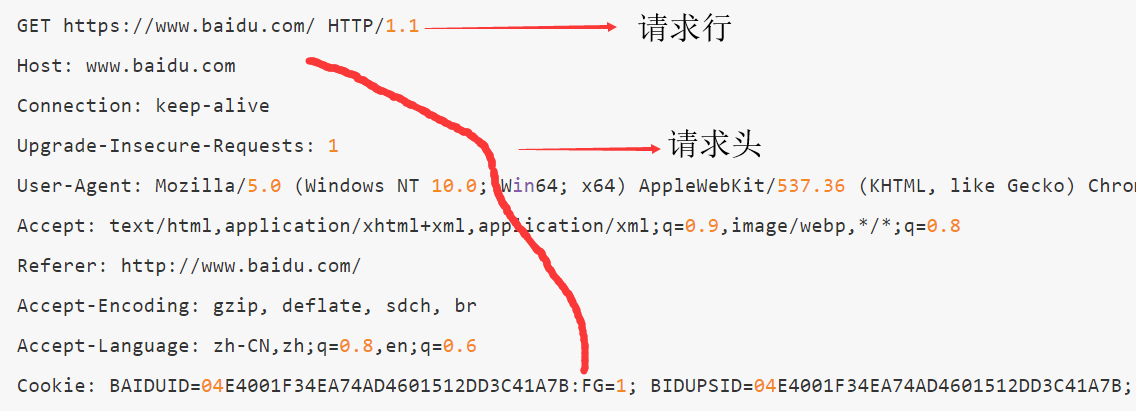
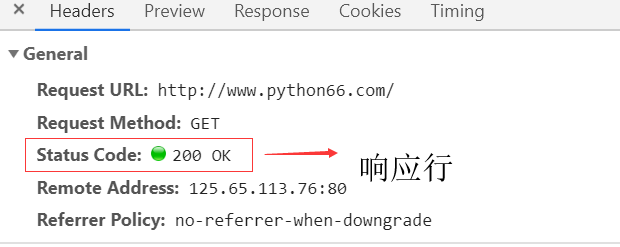
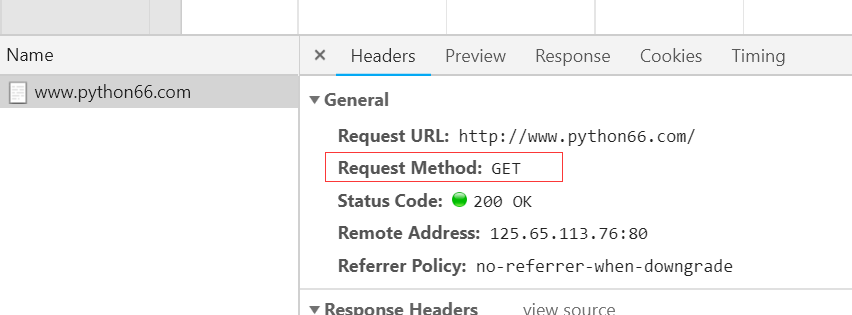
请求头和响应头使我们研究的重点。我们在浏览器上点击右键审查元素或者按f12,用浏览器访问www.python66.com这个网址就可以抓到http/https网络数据包,图示如下:
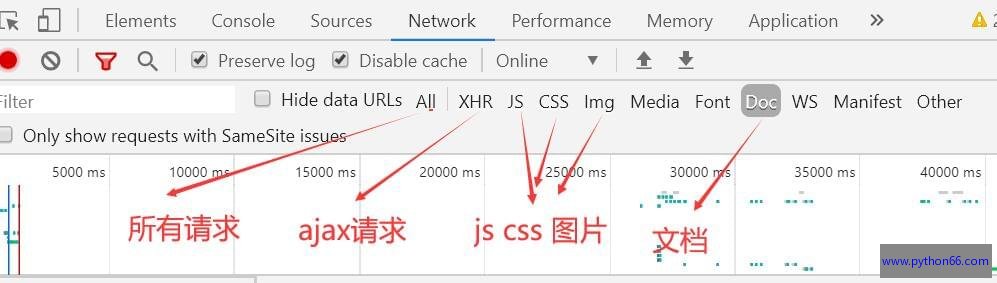
请求头(Requests Header):
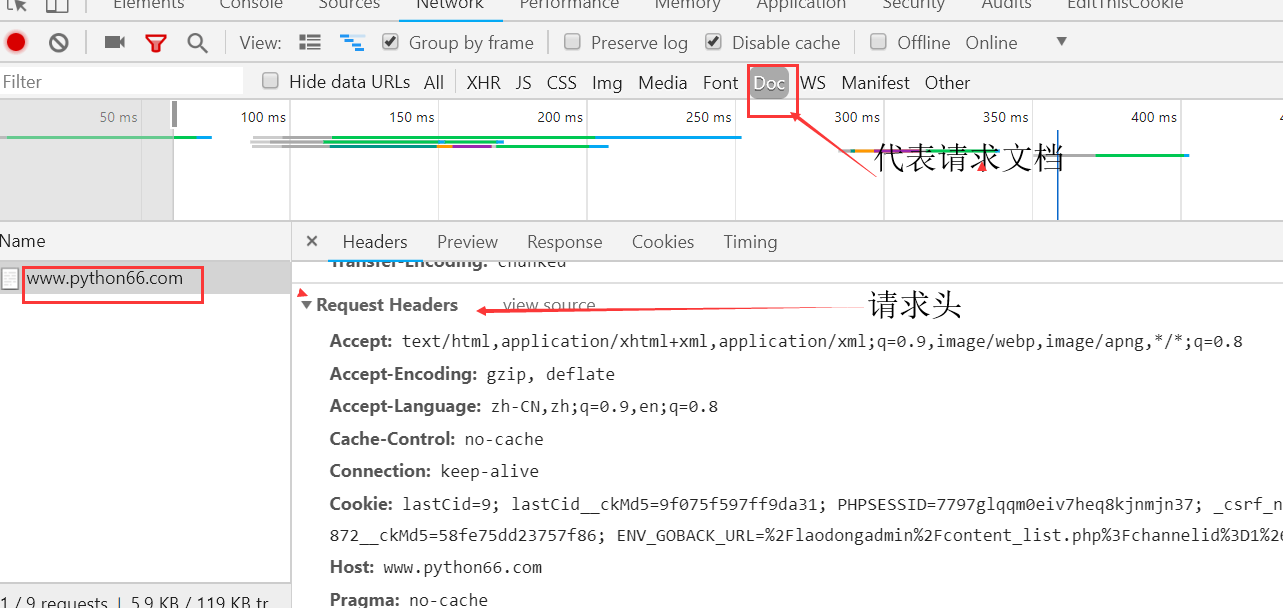
响应头(Response Headers):
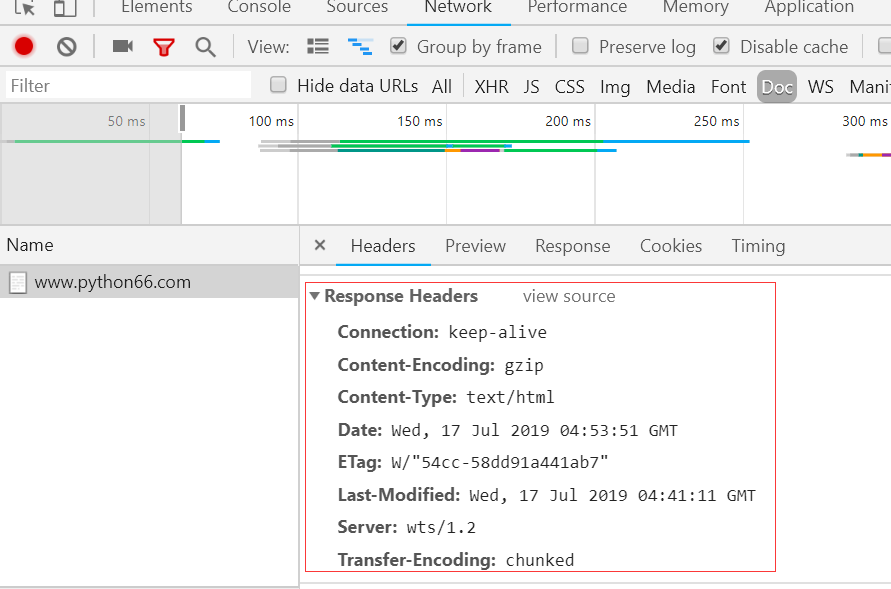
响应内容(Response):
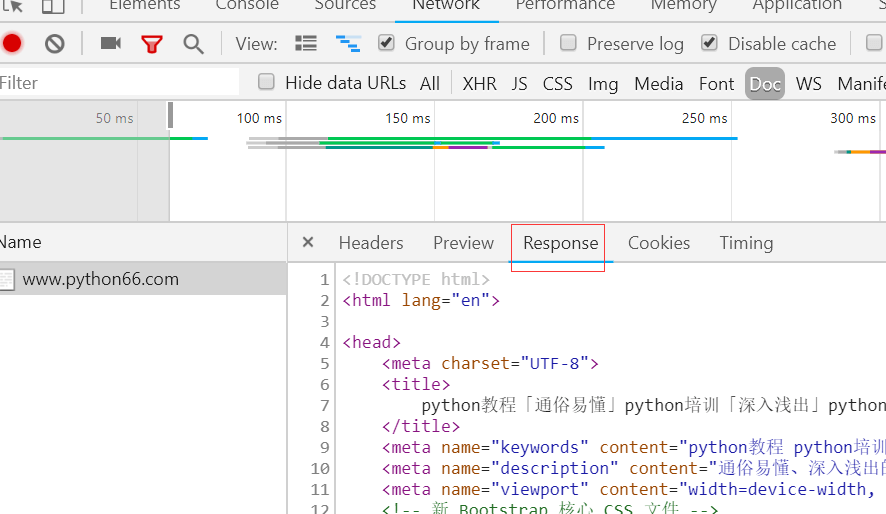
常见的请求头信息
accept:浏览器通过这个头告诉服务器,它所支持的数据类型
Accept-Charset: 浏览器通过这个头告诉服务器,它支持哪种字符集
Accept-Encoding:浏览器通过这个头告诉服务器,支持的压缩格式
Accept-Language:浏览器通过这个头告诉服务器,它的语言环境
Host:浏览器通过这个头告诉服务器,想访问哪台主机
If-Modified-Since: 浏览器通过这个头告诉服务器,缓存数据的时间
Referer:浏览器通过这个头告诉服务器,客户机是哪个页面来的 防盗链
Connection:浏览器通过这个头告诉服务器,请求完后是断开链接还是何持链接
X-Requested-With: XMLHttpRequest 代表通过ajax方式进行访问
User-Agent:请求载体的身份标识
常见的响应头信息
Location: 服务器通过这个头,来告诉浏览器跳到哪里
Server:服务器通过这个头,告诉浏览器服务器的型号
Content-Encoding:服务器通过这个头,告诉浏览器,数据的压缩格式
Content-Length: 服务器通过这个头,告诉浏览器回送数据的长度
Content-Language: 服务器通过这个头,告诉浏览器语言环境
Content-Type:服务器通过这个头,告诉浏览器回送数据的类型
Refresh:服务器通过这个头,告诉浏览器定时刷新
Content-Disposition: 服务器通过这个头,告诉浏览器以下载方式打数据
Transfer-Encoding:服务器通过这个头,告诉浏览器数据是以分块方式回送的
Expires: -1 控制浏览器不要缓存
Cache-Control: no-cache
Pragma: no-cache
http/https请求方式:
上文我们打开www.python66.com其实是get请求,get和post(提交表单数据)是http请求的两种常用方式,但是http不限于这两种方式,还有其他诸如put、delete等方式,具体如下:
| GET | 请求指定的页面信息,并返回实体主体。 |
| HEAD | 类似于get请求,只不过只获取响应头。 |
| POST | 向指定资源提交数据进行处理请求(例如提交表单或者上传文件),数据被包含在请求体中。 |
| PUT | 从客户端向服务器传送的数据取代指定的文档的内容。 |
| DELETE | 请求服务器删除指定的页面。 |
| CONNECT | HTTP/1.1协议中预留给能够将连接改为管道方式的代理服务器。 |
| OPTIONS | 允许客户端查看服务器的性能。 |
| TRACE | 回显服务器收到的请求,主要用于测试或诊断。 |
http/https响应状态码
响应状态代码有三位数字组成,第一个数字定义了响应的类别,且有五种可能取值。
常见状态码:
100~199:表示服务器成功接收部分请求,要求客户端继续提交其余请求才能完成整个处理过程。
200~299:表示服务器成功接收请求并已完成整个处理过程。常用200(OK 请求成功)。
300~399:为完成请求,客户需进一步细化请求。例如:请求的资源已经移动一个新地址、常用302(所请求的页面已经临时转移至新的url)、307和304(使用缓存资源)。
400~499:客户端的请求有错误,常用404(服务器无法找到被请求的页面)、403(服务器拒绝访问,权限不够)。
500~599:服务器端出现错误,常用500(请求未完成。服务器遇到不可预知的情况)。
补充https图示:
很赞哦!
python编程网提示:转载请注明来源www.python66.com。
有宝贵意见可添加站长微信(底部),获取技术资料请到公众号(底部)。同行交流请加群

上一篇:什么是协议?到底什么是网络协议?
相关文章
文章评论
-
http和https协议讲解-通俗而透彻文章写得不错,值得赞赏