您的位置: 网站首页> requests教程> 当前文章
requests二进制响应r.content下载图片视频及解码gzip和deflate
![]() 老董-我爱我家房产SEO2021-11-10151围观,143赞
老董-我爱我家房产SEO2021-11-10151围观,143赞
日常用爬虫采集数据除了采集文本,还会采集图片、视频等数据,requests能以字节的方式访问请求响应体获取二进制数据从而可以实现图片和视频的下载!所以对于非文本请求可以直接用r.content来获取。
下载百度百科里面的1张图片代码如下:
# -*- coding: utf-8 -*-
headers = {
'user-agent':'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.69 Safari/537.36 Edg/95.0.1020.44',
}
url = 'https://bkimg.cdn.bcebos.com/pic/b03533fa828ba61ea8d3c8f6227f800a304e241ff39d?x-bce-process=image/resize,m_lfit,w_536,limit_1/format,f_jpg'
r = requests.get(url,headers=headers)
with open('baike_py.jpg','wb') as f:
f.write(r.content)
对于文本内容用r.content获取后可以再手动decode()。
# -*- coding: utf-8 -*-
headers = {
'user-agent':'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.69 Safari/537.36 Edg/95.0.1020.44',
}
url = 'https://www.baidu.com/'
r = requests.get(url,headers=headers)
print(r.content.decode('utf-8'))
网页压缩算法
有的网页体积很大,直接传输浪费资源和时间,因此网页可以先压缩一下再传输,到了客户端后再解压缩!压缩算法有很多常见的有gzip、deflate、br。
在请求1个网页时客户端请求头增加1个字段Accept-Encoding:
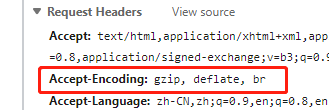
Accept-Encoding:gzip, deflate, br。这代表客户端支持gzip、deflate、br的数据解码。
在返回1个网页时,服务器端响应头里返回1个Content-Encoding字段:
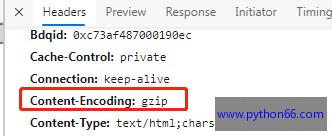
Content-Encoding:gzip。这代服务端返回gzip数据格式。
服务端也可以返回未压缩的正文,此时不允许返回Content-Encoding。
对于gzip和deflate 压缩,使用r.content后requests 会自动解码gzip和deflate传输编码的响应数据。
很赞哦!
python编程网提示:转载请注明来源www.python66.com。
有宝贵意见可添加站长微信(底部),获取技术资料请到公众号(底部)。同行交流请加群

相关文章
文章评论
-
requests二进制响应r.content下载图片视频及解码gzip和deflate文章写得不错,值得赞赏