您的位置: 网站首页> requests教程> 当前文章
requests的get请求及自定义请求头header
![]() 老董-我爱我家房产SEO2019-07-18168围观,134赞
老董-我爱我家房产SEO2019-07-18168围观,134赞
requests模块发送get请求获取网页非常简单,官方文档示例如下
r = requests.get('https://api.github.com/events')
如果拿到一个网站上来就这么请求可能拿不到数据,因为现实中很多网站都有基本的爬虫检测,检测http请求头就是基本操作,所以爬虫程序需要灵活的定制请求头。定制请求头只需要传递1个dict给get函数的headers参数即可。(不限于get请求,其他请求如post请求一样有headers参数,两者同理)
User-Agent是请求头header的一个组成部分,代表客户端的身份标识,使用浏览器发送请求,User-Agent的值就标识为浏览器。我们自定义请求头先把UA进行伪装(修改get请求的User-Agent)
# -*- coding: utf-8 -*-
import requests
headers={
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.121 Safari/537.36',
}
url = 'https://www.baidu.com/'
r = requests.get(url=url,headers=headers)
除了User-Agent,http请求头的键值对还有很多(比如Cookie、Host、Referer等),不同的网站请求头的信息可能也不一样,如果不知道添加哪些信息进去,可以直接从浏览器复制全部请求头信息然后添加到字典传参即可。
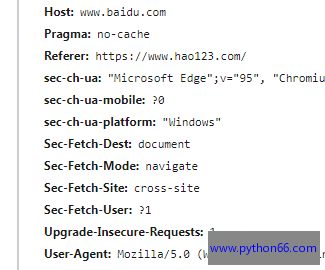
官方文档提示:所有的header值必须是string、bytestring 或者unicode。尽管传递unicode header也是允许的,但不建议这样做。
header请求头的值不可以乱填否则可能会出问题,比如我们请求www.123.com,但是Host的值填的www.python66.com,那可能会报错。
Cookie或者User-Agent的值是不允许有空格、中文的,如果不小心填上了就会报错。
1、存在中文报错
headers = {
'user-agent':'哈哈Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.69 Safari/537.36 Edg/95.0.1020.44',
}
r = requests.get('https://api.github.com/events',headers=headers)
UnicodeEncodeError: 'latin-1' codec can't encode characters in position 0-1: ordinal not in range(256)
2、存在空格报错
headers = {
'user-agent':'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.69 Safari/537.36 Edg/95.0.1020.44',
'Cookie':' xxxxx'
}
r = requests.get('https://api.github.com/events',headers=headers)
requests.exceptions.InvalidHeader: Invalid return character or leading space in header: Cookie
很赞哦!
python编程网提示:转载请注明来源www.python66.com。
有宝贵意见可添加站长微信(底部),获取技术资料请到公众号(底部)。同行交流请加群

相关文章
文章评论
-
requests的get请求及自定义请求头header文章写得不错,值得赞赏